Falcon 7B: The Small Model Beating Giants in Reasoning Tasks
Falcon 7B is challenging the long-held belief that bigger models always perform better in AI. Despite its relatively modest 7 billion parameters, this groundbreaking model outperforms competitors nearly 7 times its size—including the 32B and 47B variants of Alibaba’s Qwen and Nvidia’s Nemotron.
Thank you for reading this post, don't forget to subscribe!The Falcon H1R AI model represents a significant leap forward in reasoning capabilities. On the AIME 2025 leaderboard, a rigorous test of mathematical reasoning, it scored an impressive 83.1%, disrupting the traditional hierarchy of model sizing. This score surpasses the 15-billion parameter Apriel-v1.6-Thinker (82.7%) and the 32-billion parameter OLMo 3 Think (73.7%). Additionally, when tested on the LCB v6 benchmark, the model achieved 68.6%, which is reportedly the highest among all tested models, including those four times its size.
In this article, we’ll explore how the Falcon H1R 7B achieves these remarkable results through its hybrid architecture combining transformer and Mamba elements. We’ll also examine its extensive Falcon 7b context length of 256k tokens, its unique training methodology, and why this model might signal a fundamental shift in AI development—prioritizing architectural efficiency over simply increasing parameter count. By the end, you’ll understand why this compact powerhouse is making waves across the AI landscape.
Explore our deep dive into the latest AI Model Architectures and how they are evolving in 2026.
Hybrid Architecture of Falcon 7B: Transformer Meets Mamba
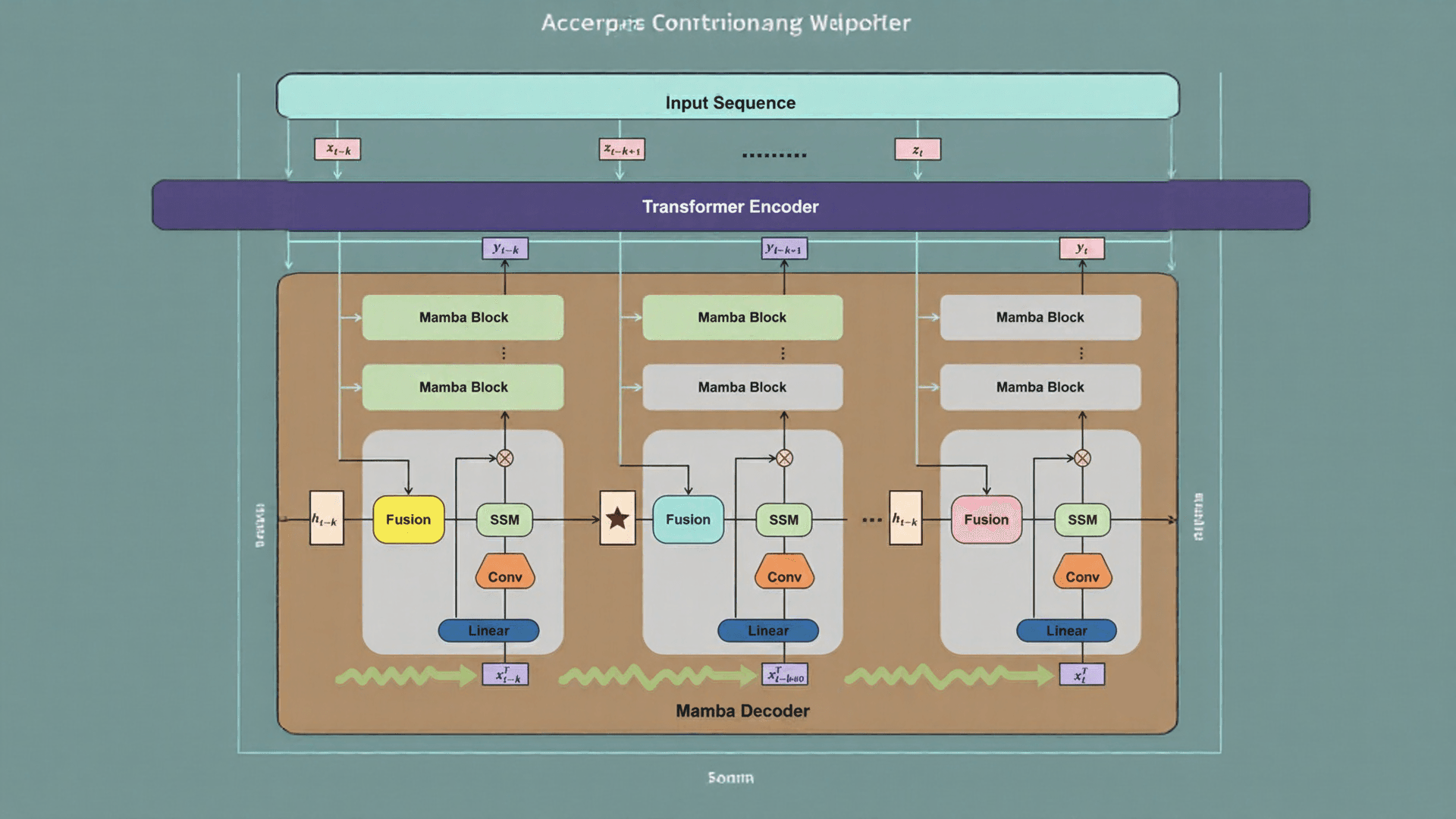
The hybrid architecture of Falcon 7B represents a fundamental departure from traditional language model designs. This innovative approach combines the strengths of Transformer-based attention mechanisms with State Space Models (SSMs), specifically the Mamba architecture, creating a powerful synergy that enables exceptional performance at a relatively small scale.
Mamba Integration for Linear-Time Sequence Modeling
At the core of Falcon 7B’s efficiency lies its implementation of Mamba-based State Space Models. Unlike Transformer models that suffer from quadratic scaling as sequence length grows, Mamba processes sequences with linear-time complexity. This architectural choice allows the model to handle extremely long contexts without the typical memory and computational bottlenecks of pure Transformer designs.
The SSM component functions as an efficient “notepad” for maintaining long-term memory throughout the sequence processing. Furthermore, Mamba’s selective state spaces enable the model to maintain constant memory usage regardless of context length. Consequently, during inference, Falcon 7B needs to attend to and store only its recurrent state rather than retaining the keys and values of all previous tokens.
Transformer Layers for High-Capacity Attention
While Mamba excels at efficient sequence processing, the Transformer layers provide crucial high-capacity attention capabilities. The attention mechanism serves as a “spotlight” that highlights relevant contextual relationships across tokens. In contrast to pure SSM designs, this hybrid approach maintains strong reasoning depth without compromising on performance.
The parallel implementation of attention and SSM heads in Falcon 7B allows for independent adjustment of each component’s ratio. Notably, research indicates that even a relatively small fraction of attention is sufficient for excellent performance when combined with Mamba. This parallel design enables faster inference and lower memory usage than pure Transformer models while maintaining comparable or superior accuracy.
256k Falcon 7B Context Length and Memory Tradeoffs
Perhaps most impressively, Falcon 7B supports a massive 256K token context window, dramatically exceeding the capabilities of similarly-sized models. This extended context capacity enables applications previously impossible at this scale, such as analyzing entire codebases, processing lengthy legal documents, or maintaining complex multi-turn conversations.
During sequential prefill operations, Falcon 7B can theoretically process prompts of arbitrary length without memory constraints. This capability exists because, unlike Transformers that store KV caches for all previous tokens, the Mamba components require no additional memory as context length increases. This efficiency translates to constant throughput and memory usage even when generating up to 130k tokens on a single GPU.
Training Pipeline: From Cold-Start to Reinforcement Learning
The unprecedented reasoning capabilities of Falcon 7B stem from its meticulously designed two-stage training pipeline, which prioritizes reasoning density without increasing parameter count.
Cold-Start SFT with 56.8% Math and 29.8% Code Tokens
Falcon 7B’s journey begins with cold-start supervised fine-tuning on a deliberately skewed dataset—56.8% of tokens devoted to mathematics and 29.8% to code. This emphasis on structured problem-solving forms the foundation for exceptional reasoning. The model processes ultra-long response sequences stretching up to 48,000 tokens, enabling it to learn complex multi-step reasoning patterns.
Difficulty-Aware Weighting for Hard Problem Emphasis
Instead of treating all examples equally, the training pipeline applies strategic difficulty-aware weighting. Hard problems are up-weighted by factors between 1.25× and 1.75×, whereas easy problems are down-weighted or entirely removed. This approach ensures the model allocates gradient budget to challenging reasoning traces rather than overfitting to trivial examples.
Balanced Token Normalization Across GPUs
To handle the immense variation in sequence lengths, the team implemented balanced data-parallel token normalization. This technique equalizes token-level gradient contributions across GPUs, preventing ranks with shorter sequences from destabilizing the loss. The approach yielded a consistent 4-10% accuracy improvement during training.
Group Relative Policy Optimization (GRPO) in RL Stage
Following SFT, the model undergoes reinforcement learning using the Group Relative Policy Optimization algorithm. GRPO computes relative advantages within groups of trajectories, automatically normalizing reward scales across problems of varying difficulty. Remarkably, the team removed the KL-divergence penalty entirely (beta=0), allowing aggressive exploration of novel reasoning paths.
Math-Only Curriculum for Cross-Domain Generalization
Perhaps counterintuitively, the RL stage focuses exclusively on mathematical problems. This approach proved superior for cross-domain generalization—ablations showed that math-focused RL improved performance globally, whereas code-only training enhanced coding scores but harmed general reasoning capabilities.
Benchmark Results: Outperforming Larger Models in Reasoning
Benchmark results reveal the surprising power of Falcon 7B against much larger counterparts. The model’s performance across specialized tasks demonstrates how effective architecture can outweigh raw parameter count.
AIME 2025: 83.1% vs Qwen 7B and Apriel 15B
Falcon H1R 7B achieved an impressive 83.1% accuracy on the AIME 2025 mathematical reasoning benchmark, substantially outperforming Qwen3-8B (65.8%). This score exceeds even the 15-billion parameter Apriel-v1.6-Thinker (80.0%) and approaches proprietary systems like Claude 4.5 Sonnet (88.0%). On AIME 2024, Falcon scored an even higher 88.1%, surpassing ServiceNow’s April 1.5 15B model (86.2%).
LCB v6 Coding Benchmark: 68.6% Top Score
On the LCB v6 coding benchmark, Falcon H1R 7B delivered 68.6% accuracy, reportedly the highest among all tested models – including those four times its size. This represents a significant improvement over comparable 8B models like Qwen3-8B (53.0%) and even larger ones like Qwen3-32B (61.0%).
General Reasoning: 49.48% vs Falcon 7X and Others
For general reasoning tasks, Falcon H1R 7B reaches 49.48%, demonstrating strong logic capabilities. It scored 61.3% on GPQA-D, matching 8B competitors (Qwen3-8B: 61.2%). On MMLU-Pro, it achieved 72.1%, outperforming all 8B rivals and approaching much larger models.
Artificial Intelligence Index v4.0 Score: 16
The model received a score of 16 on Artificial Intelligence’s Intelligence Index v4.0, placing it among stronger sub-12B models on the intelligence-parameter Pareto frontier. This independent evaluation highlighted excellent performance on specialized reasoning benchmarks, validating TII’s architectural approach.
Inference Efficiency and Test-Time Scaling
Test-Time Scaling (TTS) stands as one of Falcon 7B’s most impressive capabilities, enabling smarter reasoning without additional training. At the heart of this efficiency lies a novel approach called Deep Think with Confidence.
Deep Think with Confidence (DeepConf) Filtering
Falcon 7B implements DeepConf, a lightweight filtering method that leverages the model’s own next-token confidence scores to identify and prune low-quality reasoning paths. This system dynamically discards noisy traces during generation, effectively allocating computational resources. Indeed, DeepConf requires no additional training or hyperparameter tuning.
Token Throughput: 1,500 tokens/s/GPU at Batch 64
The hybrid Transformer-Mamba architecture enables exceptional throughput scaling. Falcon 7B processes approximately 1,000 tokens/s/GPU at batch 32 and reaches 1,500 tokens/s/GPU at batch 64. For longer contexts (8k input/16k output), it achieves roughly 1,800 tokens/s/GPU, whereas Qwen3-8B stays below 900.
38% Token Reduction vs Qwen3-8B in AIME 25
Remarkably, Falcon H1R 7B achieved 96.7% accuracy on AIME while reducing token usage by 38% compared to DeepSeek-R1-0528-Qwen3-8B. This efficiency stems from DeepConf’s ability to terminate low-performing reasoning chains early.
Pareto Frontier: Accuracy vs Token Cost
Falcon 7B establishes a new Pareto frontier in the accuracy-versus-compute tradeoff. On AMO-Bench, it achieves 35.9% accuracy using only 217 million tokens [5]. Effectively, the model delivers higher performance at lower computational cost than competitors across multiple benchmarks.
Conclusion
Falcon 7B undoubtedly represents a paradigm shift in the AI model landscape. This compact 7-billion parameter model has defied conventional wisdom by outperforming competitors many times its size across critical reasoning benchmarks. The key to its success lies primarily in architectural innovation rather than parameter count.
The hybrid architecture combining Transformer attention mechanisms with Mamba-based State Space Models creates a powerful synergy. Consequently, the model achieves linear-time sequence processing while maintaining high-capacity attention capabilities. This innovative design enables the impressive 256k token context window without the memory constraints typical of pure Transformer models.
Additionally, the two-stage training pipeline with its heavy emphasis on mathematics and code has proven remarkably effective. The strategic difficulty-aware weighting and balanced token normalization strategies ensure the model allocates resources to challenging reasoning traces. Likewise, the Group Relative Policy Optimization approach during reinforcement learning allows for aggressive exploration of novel reasoning paths.
The benchmark results speak for themselves. Falcon H1R 7B achieved 83.1% accuracy on AIME 2025, outperforming models with up to 15 billion parameters. Similarly, its 68.6% score on the LCB v6 coding benchmark reportedly surpasses all tested models, including those four times larger.
Perhaps most significantly, the model establishes a new Pareto frontier in the accuracy-versus-compute tradeoff. The Deep Think with Confidence filtering method dynamically discards low-quality reasoning paths, reducing token usage by 38% compared to similar-sized competitors while maintaining superior accuracy.
Falcon 7B demonstrates that the future of AI might not depend on ever-increasing model sizes but rather on smarter architectures and training methodologies. This efficiency-focused approach could make advanced AI capabilities more accessible and sustainable. As the field evolves, we expect to see more innovations prioritizing architectural elegance over brute-force scaling—a trend Falcon 7B has certainly accelerated.
FAQs
Q1. What makes Falcon 7B unique compared to larger language models? Falcon 7B stands out for its hybrid architecture combining Transformer and Mamba elements, allowing it to outperform much larger models in reasoning tasks despite having only 7 billion parameters.
Q2. How does Falcon 7B achieve its impressive context length? Falcon 7B supports a 256K token context window through its efficient Mamba-based State Space Models, which process sequences with linear-time complexity and maintain constant memory usage regardless of context length.
Q3. What training approach was used for Falcon 7B? The model underwent a two-stage training pipeline, starting with supervised fine-tuning heavily focused on mathematics and code, followed by reinforcement learning using Group Relative Policy Optimization with a math-only curriculum.
Q4. How does Falcon 7B perform on benchmark tests? Falcon 7B achieved 83.1% accuracy on AIME 2025, 68.6% on the LCB v6 coding benchmark, and 49.48% on general reasoning tasks, outperforming many larger models across these benchmarks.
Q5. What is Deep Think with Confidence (DeepConf), and how does it improve efficiency? DeepConf is a filtering method used by Falcon 7B that leverages the model’s confidence scores to identify and prune low-quality reasoning paths during generation, improving efficiency without additional training or tuning.